Hätten wir es nur mit einer einzigen Struktur-Ebene zu tun, wäre die Antwort leicht: Eine Struktur wäre dann einfacher als eine andere, wenn sie aus weniger Elementen und Relationen bestünde. Wir hatten jedoch bereits im Rahmen der Beschreibung des allgemeinen Modells für Software-Systeme ausgeführt, dass Software-Systeme hierarchisch aufgebaut sind somit mehrere Struktur-Ebenen aufweisen. Wir sehen uns daher vor die Aufgabe gestellt, die Grundlagen einer strukturellen Betrachtungsweise unter Berücksichtigung mehrerer Ebenen zu erarbeiten.
1. Elemente und Relationen auf verschiedenen Struktur-Ebenen

2. Grundidee: Reduktion von Elementen und Relationen
Die naheliegende Grundidee zur Vereinfachung einer Struktur besteht darin, die Zahl der Elemente und Relationen so gering wie möglich zu gestalten. Dies könnte dazu verleiten, die Elemente einer Ebene so weit als möglich zu verschmelzen: Die Verschmelzung reduziert zugleich die Anzahl der Elemente als auch der Relationen. Bedauerlicherweise ignoriert diese Vorgehensweise zwei wesentliche Aspekte:- Ursprung der Relationen: Der Ursprung aller Relationen eines Software-Systems, gleich auf welcher Ebene sie betrachtet werden, liegt im Bereich der Funktionen und Daten.
- Aktuale vs. potentielle Struktur: Die Einfachheit einer Struktur resultiert nicht nur aus der Anzahl der tatsächlich vorhandenen (aktualen) Relationen, sondern auch aus der Anzahl der möglichen (potentiellen) Relationen.
3. Funktionen und Daten als Ursprung aller Relationen
Der Ursprung aller Relationen auf den verschiedenen Struktur-Ebenen eines Software-Systems liegt im Bereich der Funktionen und Daten. Betrachten wir zur Erläuterung dieses Sachverhalts die verschiedenen Ebenen des allgemeinen Modells für Software-Systeme, wobei wir uns hier auf die logische Dimension konzentrieren und die physische ausblenden. (Das Gesamtmodell wird im Abschnitt "3.3.1. Allgemeine Systemhierarchie" im Artikel über das allgemeine Modell für Software-Systeme beschrieben.)
Bei der Projektion einer funktionalen Relation auf eine höhere Ebene kommt es häufig zu einer scheinbaren Vereinfachung. Denn mehrere funktionale Relationen zwischen zwei Typen werden auf der Typ-Ebene auf eine Relation reduziert. Mehrere Typ-Relationen zwischen zwei Paketen werden auf Paket-Ebene auf eine Relation reduziert usw. Mit dieser scheinbaren Vereinfachung geht ein Informationsverlust auf der höheren Ebene einher. Dieser Informationsverlust ändert aber nichts am tatsächlichen Umfang der weiterhin vorhandenen funktionalen Relationen.
4. Aktuale vs. potentielle Struktur
Die aktuale Struktur einer Ebene wird durch die tatsächlich vorhandenen Elemente auf dieser Ebene sowie die tatsächlich vorhandenen Relationen dieser Elemente bestimmt. Da die scheinbare Vereinfachung der Relationen auf höheren Ebenen letztlich nur auf einem Informationsverlust beruht, ergibt sich die Komplexität der aktualen Gesamtstruktur im Wesentlichen aus den tatsächlich vorhandenen funktionalen Relationen. Ich bezeichne diese Komplexität im Folgenden als aktuale Strukturkomplexität.Die aktuale Strukturkomplexität ist jedoch nicht gleich der Strukturkomplexität des Gesamtsystems. Diese wird wesentlich mitbestimmt durch die Anzahl der möglichen funktionalen Relationen, die ich im Folgenden als potentielle Strukturkomplexität bezeichne. Während sich die aktuale Strukturkomplexität ausschließlich aus den tatsächlich realisierten funktionalen Relationen ergibt und von höheren Struktur-Ebenen völlig unabhängig ist, gilt dies für die potentielle Strukturkomplexität keineswegs. Dies hängt damit zusammen, dass der Zugriff auf Funktionen und Daten durch höhere Struktur-Ebenen eingeschränkt werden kann.
Denn höhere Struktur-Ebenen sind keine reinen Gruppierungen ihrer enthaltenen Elemente, sondern können auch die Sichtbarkeit ihrer Elemente nach außen hin einschränken. Ist eine Funktion oder ein Daten-Objekt außerhalb eines solchen Struktur-Elements nicht sichtbar, so steht es außerhalb dieses Elements auch nicht für die Bildung funktionaler Relationen zur Verfügung. Daraus resultiert eine Reduktion der potentiellen Strukturkomplexität des Gesamtsystems.
Wir können nun die Strukturkomplexität wie folgt definieren:
CS = a * Ca + (Cp - Ca) + b * |E|mit
- CS = Strukturkomplexität
- Ca = aktuale Strukturkomplexität = Anzahl der aktualen funktionalen Relationen
- Cp = potentielle Strukturkomplexität = Anzahl der potentiellen funktionalen Relationen
- |E| = Anzahl der Funktionen und Daten-Objekte
- a = Gewichtungsfaktor der aktualen gegenüber der potentiellen Struktur
- b = Gewichtungsfaktor für die Anzahl der Elemente
In der Formel wird Ca von Cp abgezogen, da die mit a gewichtete aktuale Strukturkomplexität bereits in die Summe eingeflossen ist und nicht ein weiteres Mal einfließen soll. Für die weitere Betrachtung werde ich a = 1 setzen und die Anzahl der Elemente ignorieren, also b = 0 setzen. Dies reicht aus, um das für diesen Artikel Wesentliche zu erfassen. Es ergibt sich die folgende vereinfachte Formel:
CS = CpDie angestellte Betrachtung liefert uns nun das Handwerkszeug, um zu verstehen, warum triviale Verschmelzungen auf einzelnen Struktur-Ebenen nicht den gewünschten Effekt einer Vereinfachung haben, sondern im Gegenteil die Komplexität erhöhen können.
5. Beispiel einer kontraproduktiven "Vereinfachung"
Wir betrachten ein System aus zwei Typen A und B mit jeweils zwei Funktionen, die als A.a, A.b, B.x und B.y bezeichnet werden. Das aktuale System sieht auf den drei Ebenen System, Typ und Funktion wie folgt aus: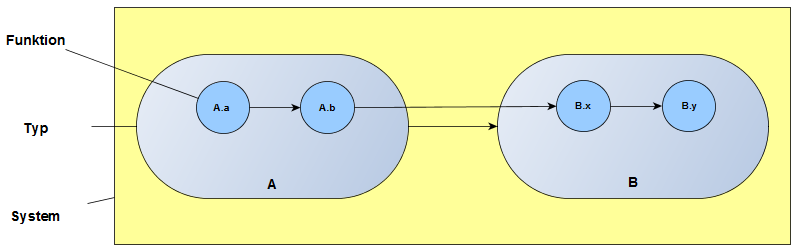
CS = Cp = 6Wir möchten dieses System nun "vereinfachen", indem wir die Typen A und B zum Typ A' verschmelzen. Dies führt zu folgendem System:

CS = Cp = 12Die Steigerung wächst mit der Zahl der Elemente quadratisch an, so dass die Verschmelzung größerer Elemente ggf. zu einer erheblichen Komplexitätssteigerung führt.
6. Fazit
Die oben angestellten Überlegungen haben zu einigen interessanten Erkenntnissen geführt:- Betrachtet man ausschließlich das tatsächlich realisierte System, so spielt die Aufteilung der Funktionen und Daten-Objekte auf die diversen Gruppierungen höherer Ebenen (wie Typen, Pakete, Subsysteme usw.) keine Rolle für die beobachtete strukturelle Komplexität (=aktuale Strukturkomplexität) des Systems.
- Die Strukturierung dieser höheren Ebenen, d. h. die Aufteilung der Funktionen und Daten-Objekte auf Typen, Pakete, Subsysteme usw. ist jedoch sehr bedeutsam für die Größe des strukturellen Lösungsraums (= potentielle Strukturkomplexität) eines Systems und damit auch für die tatsächlichen Ressourcen, die im Umgang mit dem System benötigt werden.
- In einem völlig unstrukturierten System, in dem alle Funktionen und Daten-Objekte in potentieller Relation zueinander stehen, ergibt sich die Gesamtkomplexität als |E| * (|E| - 1), sie steigt also quadratisch zur Anzahl der Funktionen und Daten-Objekte. Wir haben für die Zwecke dieses Artikels die Anzahl der Elemente sowie ihre durchschnittliche Komplexität ignoriert und können die Formel daher in dieser Weise vereinfachen. An dieser Stelle sollte aber klar geworden sein, dass die angestrebte strukturelle Vereinfachung insbesondere durch Einschränkung des Zugriffs auf Funktionen und Daten-Objekte erreicht werden kann und dass zu diesem Zweck die entsprechenden Mittel höherer Struktur-Ebenen eingesetzt werden können.